Blog
August 6, 2021
How to Extract Data From Files With JMeter

Open Source Automation,
Performance Testing
When it comes to software performance testing, it’s crucial that you can reuse response data. Almost (if not all!) load test scenarios assume that you:
Extract interesting aspects from a previous response and reuse them in the next request (a.k.a Correlation)
Ensure the actual response matches expectations (a.k.a. Assertion)
So, if you’re a performance test engineer, it’s super important that you know how to implement this correlation and assertion logic. Luckily, BlazeMeter’s Knowledge Base and the JMeter Blog already have some great articles on how to do this. Check out the following:
Using RegEx (Regular Expression Extractor) with JMeter - to parse responses using Perl5-style regular expressions
Using XPath and JSON Path Extractors in JMeter - to deal with XML/XHTML and JSON data
How to Use JMeter Assertions in 3 Easy Steps - to apply an assertion to the response and conditionally set pass or fail criteria
These are all great approaches for text-based responses. But what if you need to extract something from a binary file? What if, for example, you need to validate the content of a Microsoft Word document coming as a HTTP Request Sampler response?
This is exactly the kind of challenge that I’m going to tackle in this article. I’ll guide you through the process of viewing and obtaining the content of different document types, including Microsoft Office, OpenOffice, ZIP archives and multimedia files.
Back to top
How to View the Content of Binary Files
Before we start, make sure you know how to use JMeter’s View Results Tree Listener - as it’s incredibly useful for the visualization and inspection of request and response details. If you’re not familiar with it, take a look at this article: How to debug your Apache JMeter script
Now let’s start with a very basic Microsoft Excel compatible spreadsheet. I took a 3.6KB Microsoft Office Excel Worksheet.

As you can see, we have the file test.xlsx with one worksheet labelled ‘Sheet1’. In cell A1, we have the string foo, and in cell B1, we have the string bar.
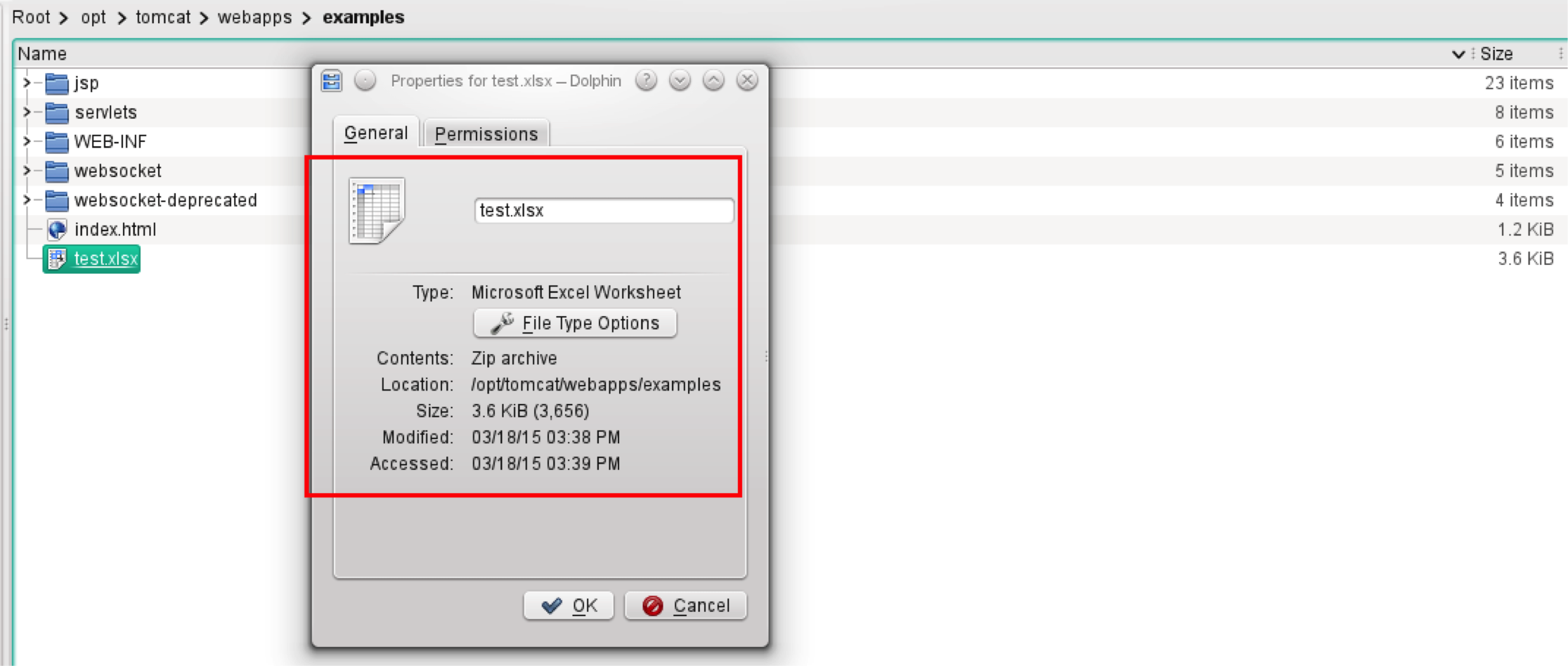
Now it’s time to use the ‘View Results Tree Listener’ to understand how JMeter sees it.
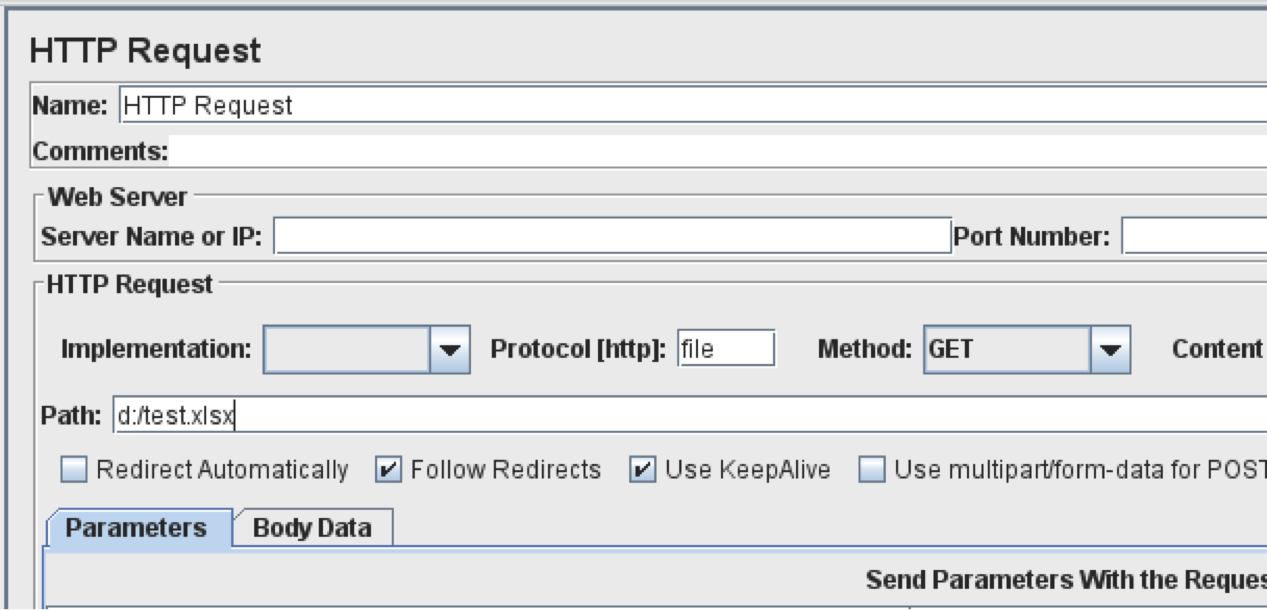
I used my local Apache Tomcat application server to get the “test.xlsx” file, but JMeter’s HTTP Request sampler can also pick up files from your local file system. Just enter “file” in the “Protocol” field and give the full path in “Path” field (as in the screenshot below).
Here’s how the Sampler Results tab looks in the ‘View Results Tree Listener’:
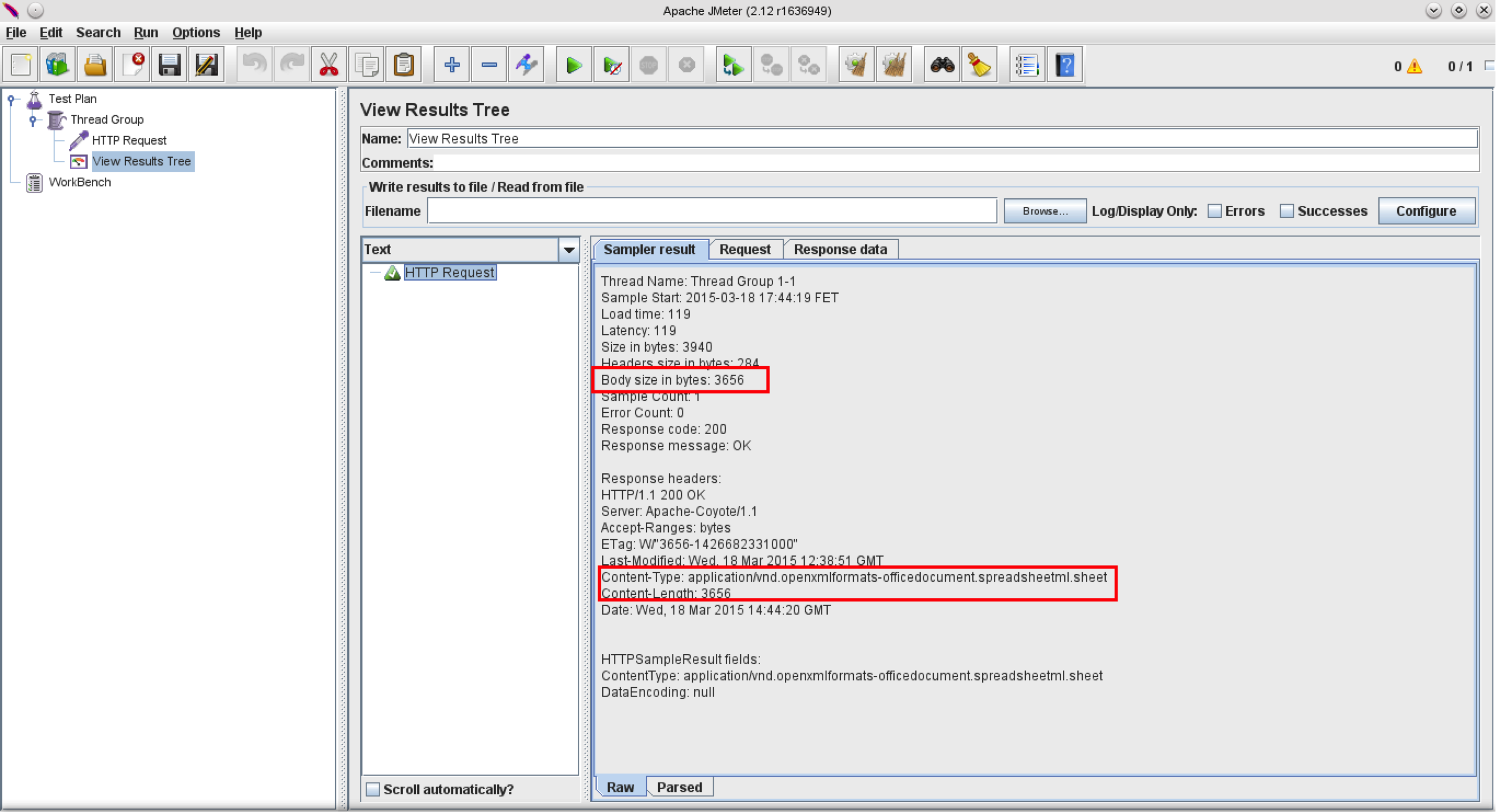
This shows that JMeter recognizes the MIME Type (“application/vnd.openxmlformats-officedocument.spreadsheetml.sheet”) and reports the correct response body size of 3656 bytes.
Now let’s take a look at “Response Data” tab:
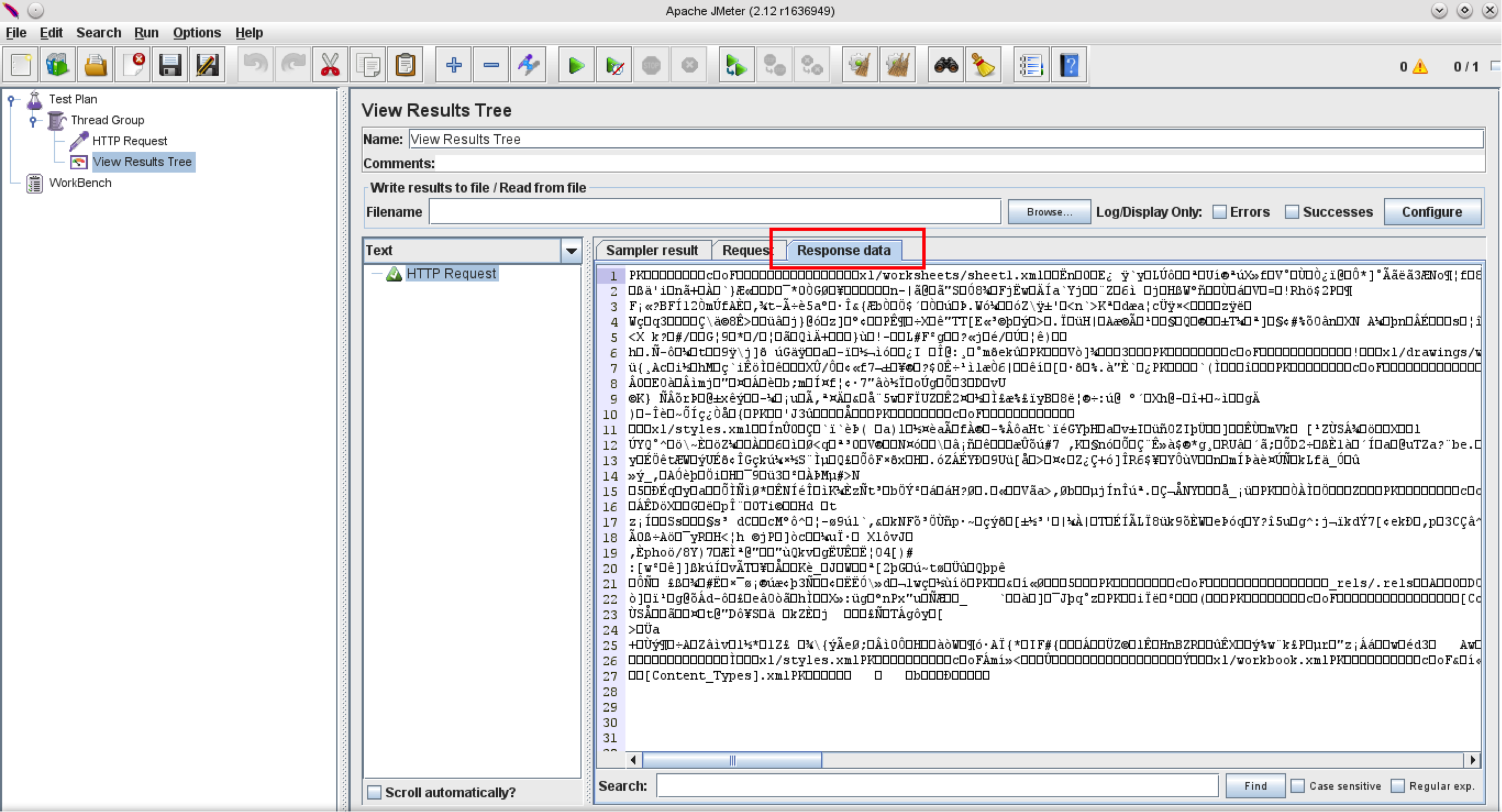
This shows a text representation of the ZIP archive - which isn’t readable due to its binary nature.
The View Results Tree Listener gives you a few options on how the response data can be displayed. It can parse HTML, XML, JSON, provide Regex, CSS and XPath testing capabilities, and also display content from different document types (to do this, you’ll need to change the default option “Text” to “Document” in the drop-down in the upper-left corner)
Let’s switch to the “Document” option

Now we can see that “tika-app.jar” is missing from JMeter’s CLASSPATH. To enable non-text based responses parsing, you’ll need to download tika-app-*.jar from the Apache Tika download page and drop it into the /lib folder of your JMeter installation. The Asterisk (*) here stands for the version. The latest one should be fine but if it doesn’t work, look for tika-core-*.jar and tika-parsers-*.jar files in JMeter’s /lib folder and download the relevant tika-app.jar.
Here are some examples:
JMeter 2.12 comes with the tika-core-1.6.jar and tika-parsers-1.6.jar. So it’s worth downloading tika-app-1.6.jar if you’re using JMeter 2.12
JMeter 2.13 comes with the tika-core-1.7.jar and tika-parsers-1.7.jar. In this case you’ll need tika-app-1.7.jar
Having said this, I do recommend using the latest JMeter version if at all possible because it will contain bug fixes, performance improvements and new features.
After you add the tika-app-*.jar to the /lib folder, it’s important to restart all running instances of JMeter instances as the process of picking up external .jar files isn’t dynamic. This also applies to JMeter Plugins, JUnit Tests, etc.
So let’s see how the response looks with the tika-app.jar added to JMeter’s classpath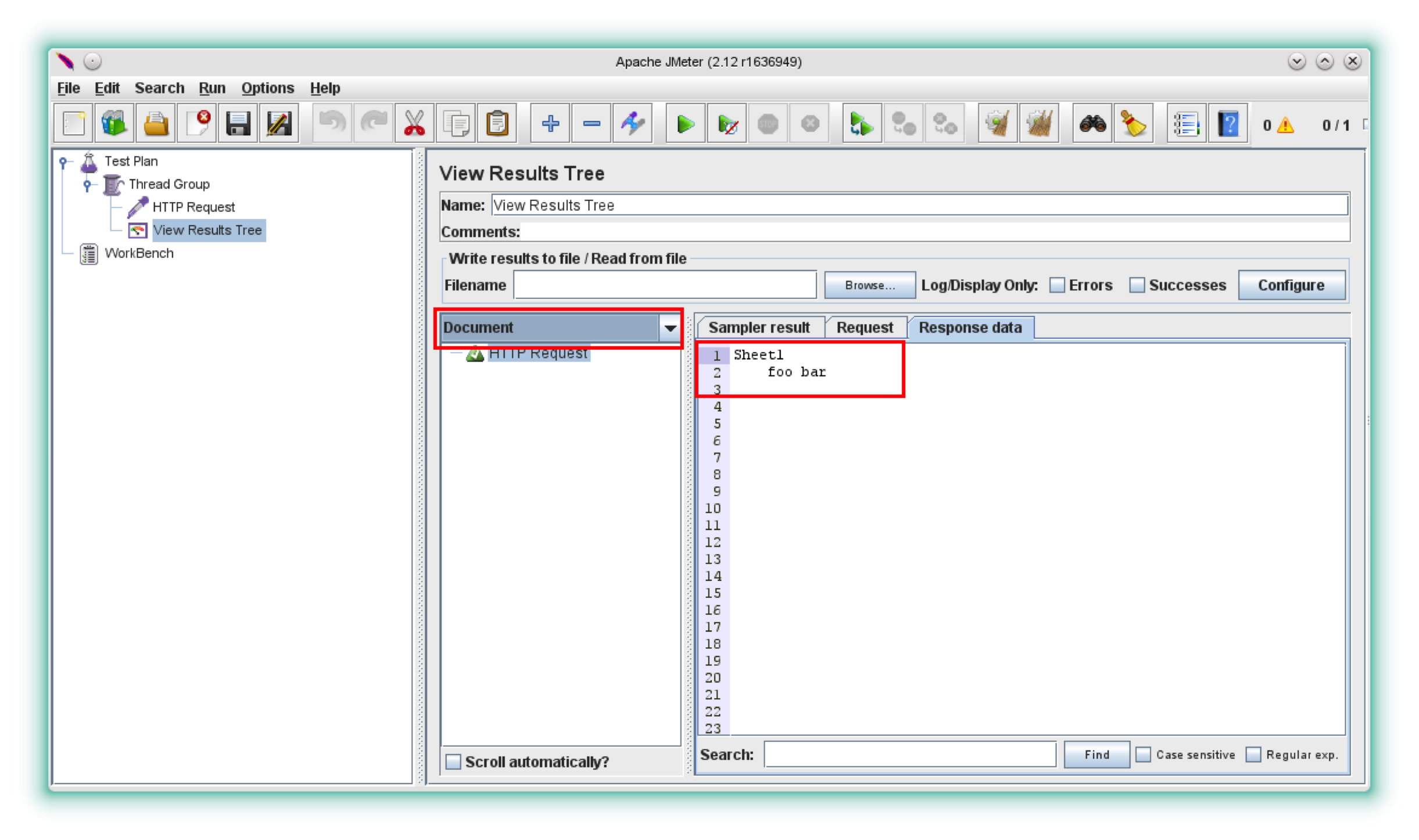
Now we can see the title of the worksheet along with the values of the A1 & B1 cells.
Back to topHow to Access the Content of Binary Files
Sometimes it’s not enough just to ‘see’ the content. What if you need to do something with the extracted data, like use it as a parameter for the next request or verify that the actual response contains the “foo” string?
Let’s see if we can use the Regular Expression Extractor to fetch content from an Excel document. First of all, let’s save the whole response into a JMeter Variable.
Back to top
How to Save the Sampler Response Into a JMeter Variable
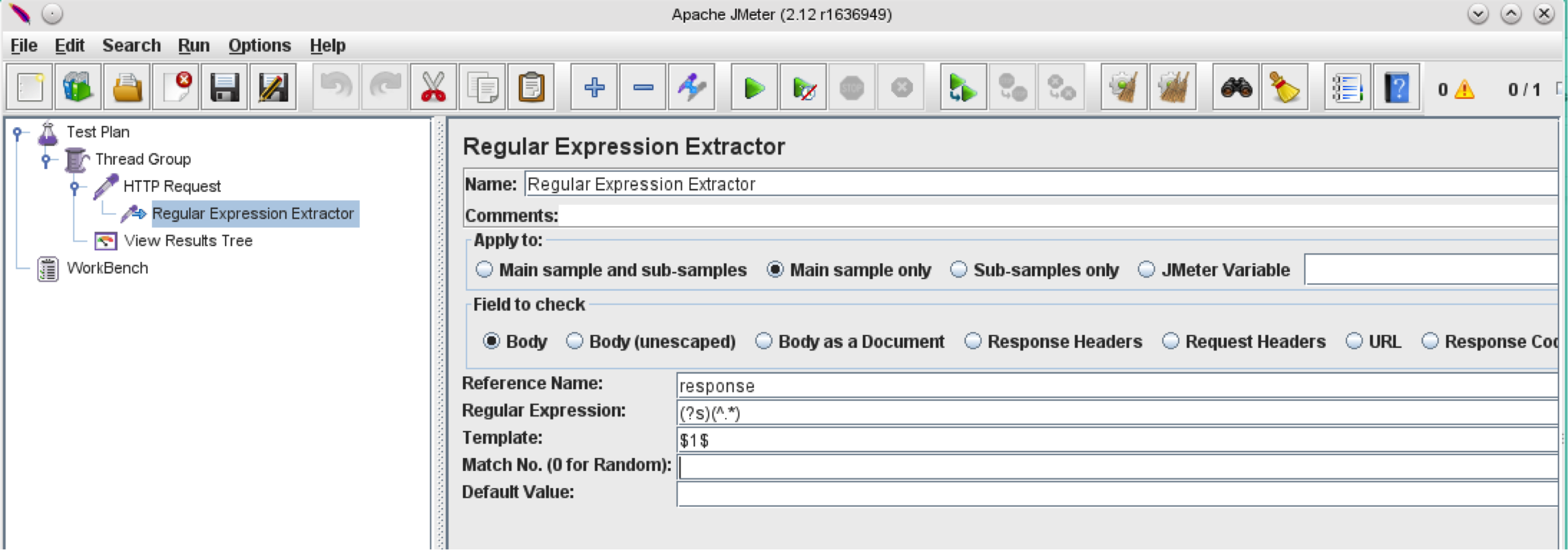
Here I’m going to show you how to construct a regular expression that matches the whole response.
Take a look at the Regular Expressions section of JMeter’s User Manual. Here we can identify meta and control characters to develop a regular expression which match everything in the response:
() = grouping
(?s) = single line modifier
^ = line start
. = wild-card character
* = repetition
So, a regex which will return the whole response should look like this:
(?s)(^.*)
And the entire Regular Expression Extractor Post Processor should look like this:
Now we want to see the “response” variable value. Let’s add a Debug Sampler between the HTTP Request and View Results Tree Listener and run the test again.
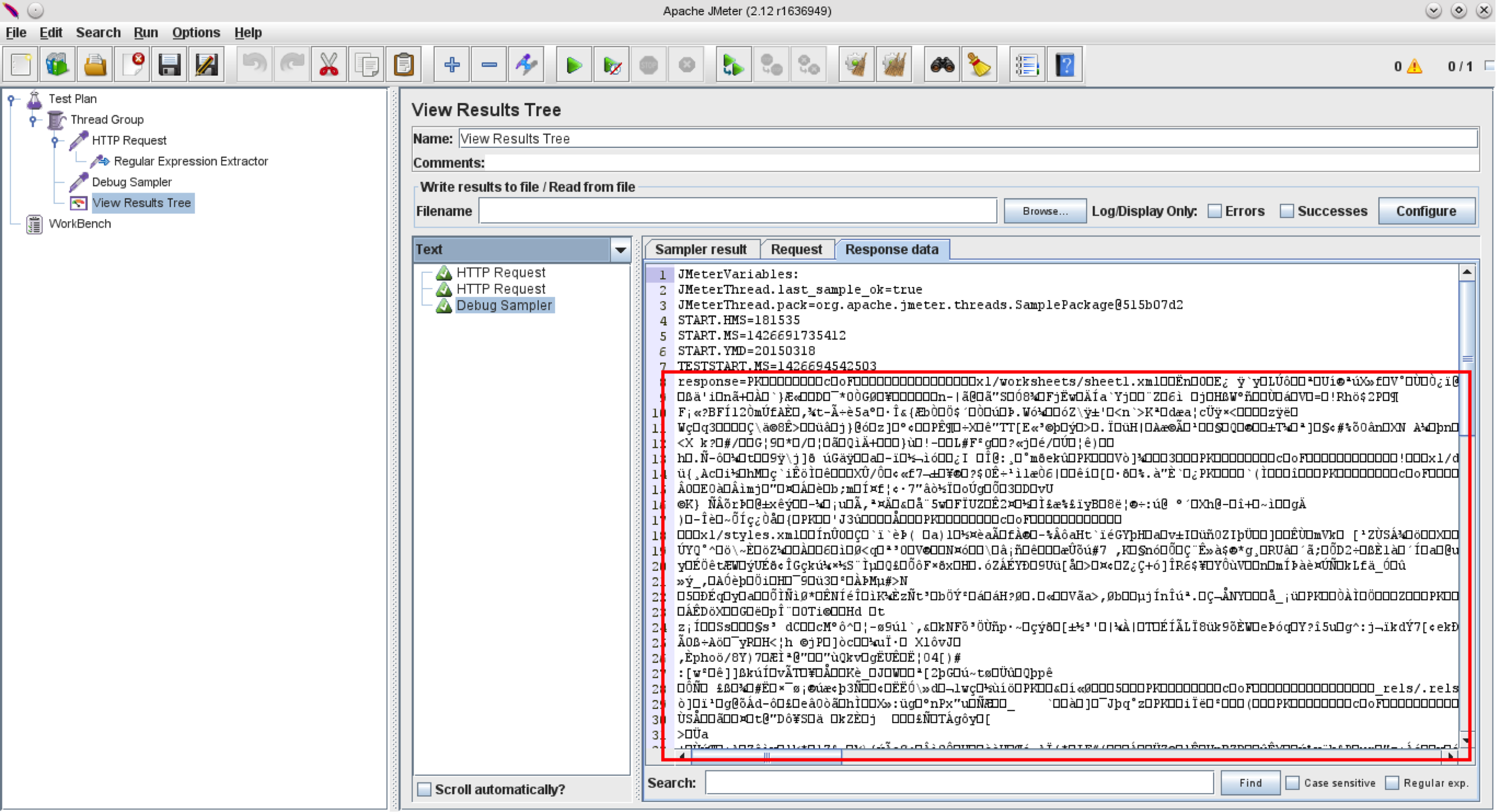
This is a bit disappointing! :(
Clearly, the Regular Expression Extractor doesn’t work with the parsed response, it just returns the binary file content which isn’t very usable or helpful. But if JMeter shows the Excel file content, it should be possible to get it. Let’s go deeper and see how JMeter’s View Results Tree Listener displays the Excel file content.
And here it is: org.apache.jmeter.util.Document.String getTextFromDocument(byte[] document). As it states here, you use Apache Tika to convert many kinds of documents (including odt, ods, odp, doc(x), xls(x), ppt(x), pdf, mp3, mp4, etc.) to text.
So let’s remove the Regular Expression Extractor and add a Beanshell Post Processor instead.
Insert the following code into Beanshell’s Post Processor’s “Script” arimport org.apache.jmeter.util.Document;
String converted = Document.getTextFromDocument(data);
vars.put("response", converted);
where:
Line 1 - Import to resolve the Document class
Line 2 - Invoke the getTextFromDocument method
data - this is a pre-defined Beanshell variable which holds the parent sampler response as byte array
store result into a converted string object
Create a JMeter Variable response and assign it with the value of converted string
See How to use BeanShell: JMeter's favorite built-in component guide for more info on Beanshell’s scripting domain and more useful tips and tricks.
Now let’s retry the request and see how it goes this time.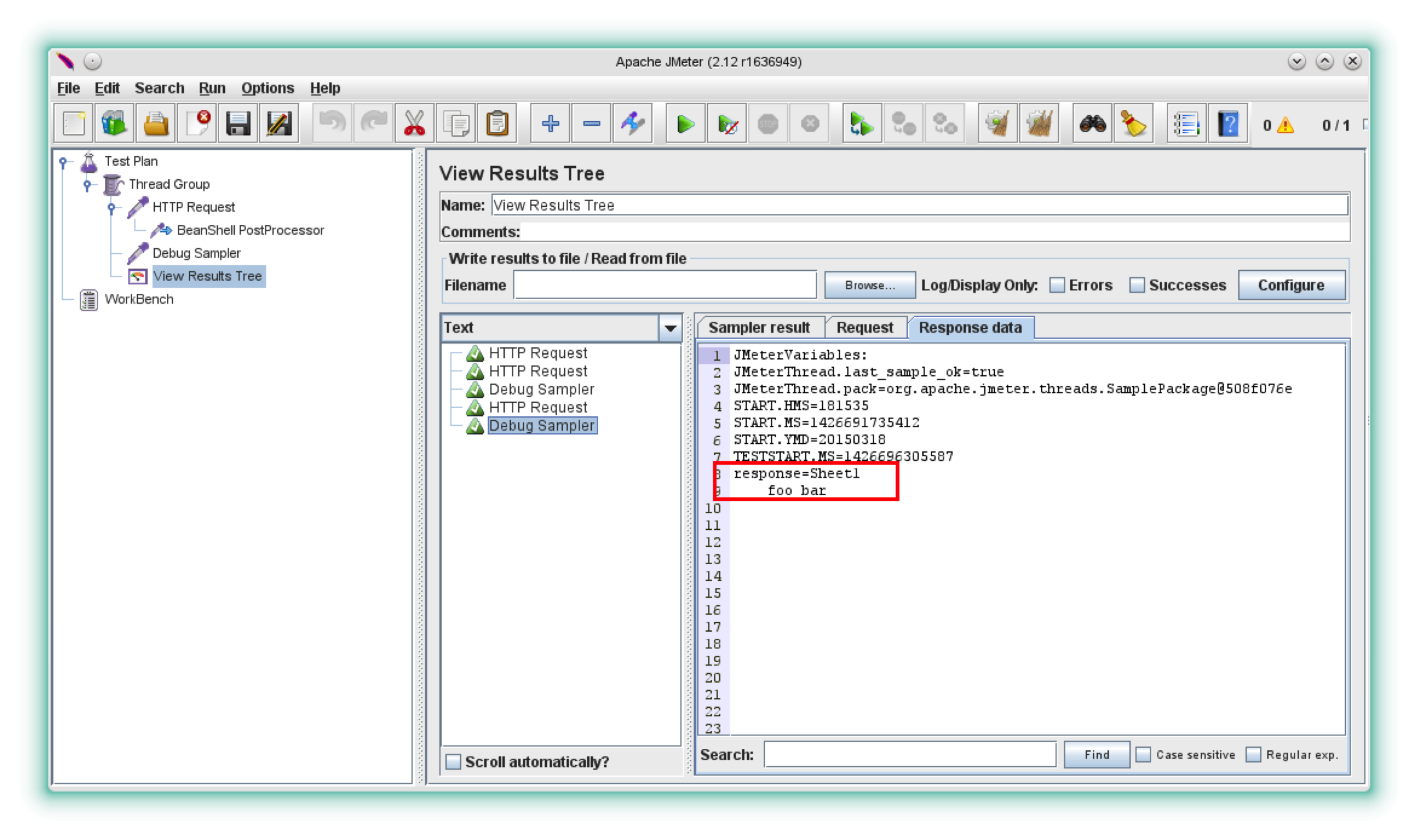
As you can see, you can now refer to the whole file content as: ${response} JMeter Variable. What’s more: you can apply post processors and assertions to it.
Back to top
How to Parse Binary Files
Finally, let’s look at how we can work with binary files in a smarter way. I’ve already covered how to get binary file content into a JMeter Variable, now I’m going to look at how to access individual elements.
Let’s take our example Excel file and extract values from the A1 and B1 cells.
The Apache Tika binary includes several libraries which are able to work with document file types, multimedia files, archives, etc. It uses the Apache POI API for Microsoft file types so we’ll need to work with Apache POI classes to extract the cell content from Excel documents (take a look at the POI Quick Guide on working with Spreadsheets for code samples and more info on how to do this).
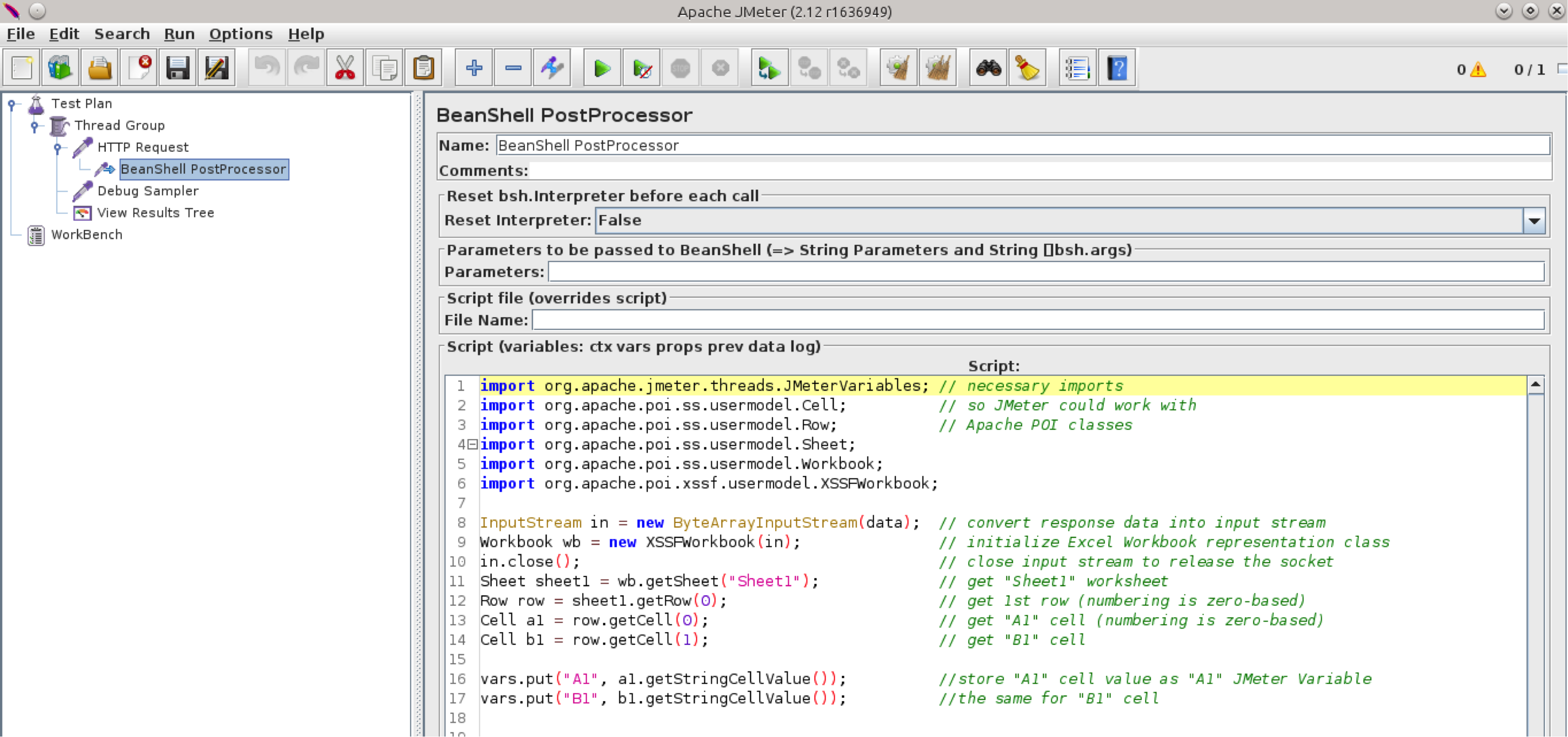
So the code from our example will look like this:
import org.apache.jmeter.threads.JMeterVariables;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
InputStream in = new ByteArrayInputStream(data);
Workbook wb = new XSSFWorkbook(in);
in.close();
Sheet sheet1 = wb.getSheet("Sheet1");
Row row = sheet1.getRow(0);
Cell a1 = row.getCell(0);
Cell b1 = row.getCell(1);
vars.put("A1", a1.getStringCellValue());
vars.put("B1", b1.getStringCellValue());
Which means that our Beanshell PostProcessor will look like this:
Let’s run our test once more and see the variable values of A1 and B1 in the Debug Sampler
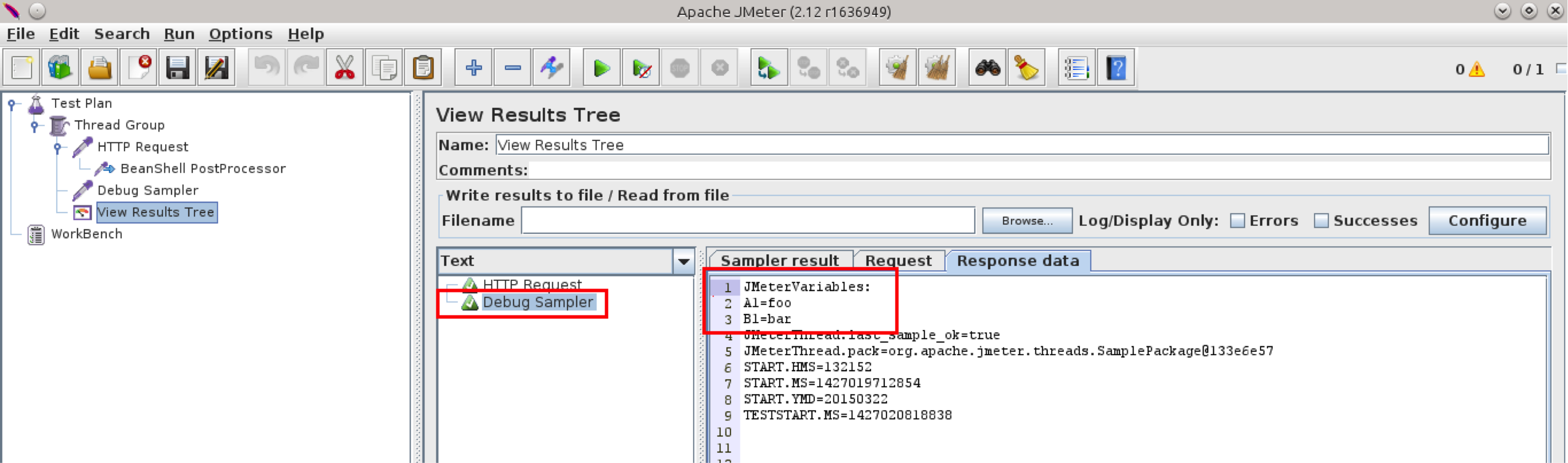
As you can see, there are two variables (excluding the pre-defined ones)
A1=foo
B1=bar
${A1} and ${B1} can be used as parameters, targets for postprocessors, assertions etc.
That’s it!! Now we know how to extract data from Excel documents using JMeter and Tika.
This is only one out of Apache Tika’s 300+ formats - but I don’t think I can cover all of them in one blog post! If you’re using something other than Excel, take a look at the Tika Supported Formats Page to determine the implementation library and class. Then read the documentation to learn how to extract it properly.
Just two final points:
- BlazeMeter’s systems fully support the data extraction of documents - as long as you provide the tika-app-*.jar with your test script and other files.
- If you have any problems with this or any other JMeter functionality, please share in the comments pane below. I’ll do my best to respond asap!